Scientific Emphasis Proceedings, June 01, 2001 © Essem 2001
The new decade will be characterized by the availability of multiple access devices that enable ubiquitous access to information. The ability to access and transform information via a multiplicity of appliances, each designed to suit the user's specific usage environment, necessarily means that these interactions will exploit all available input and output modalities to maximize the band-width of man-machine communication.
This paper outlines "single authoring" as a new programming model for authoring once for the Next Web, multi-modal web or mobile internet, where information is expected to be accessible anytime, anywhere, through any device and where the user can at any given time select to use the device and modality best suited to his or her abilities and capabilities at that moment.
We address the challenges of designing user interfaces and building applications that work across these multiplicities of information appliances; it motivates the introduction of single authoring. In addition, amongst the key issues addressed are the user's ability to interact in parallel with the same information via a multiplicity of appliances and user interfaces, and the need to present a unified, synchronized view of information across the various appliances that the user deploys to interact with information. We achieve such synchronized interactions and views by adopting the well-known Model, View, Controller (MVC) design paradigm and adapting it to conversational interactions and the single authoring programming model.
Keywords: User Interfaces and Interaction, Interoperability, Web Accessibility, Browsers and tools, Web Applications, Content and coding, XML, Architecture issues.
This paper outlines single authoring as a new programming model for authoring once for the Next Web, multi-modal web or mobile internet, where information is expected to be accessible anytime, anywhere, through any device and where the user can at any given time select to use the device and modality best suited to his or her abilities and capabilities at that moment.
The problem of device-independent authoring is similar to the issues of authoring applications to be rendered in different modalities or multiple synchronized modalities [1,3].
We first define some terminology:
- channel: it denotes a particular device or a particular
modality.
- multi-channel applications: applications designed
for ubiquitous access through different channels, one channel at a time.
- multi-modal applications: multi-channel applications,
where multiple channels are simultaneously available and synchronized.
For the Next Web, new content and applications are developed with the intent of delivering it through many different channels with different characteristics. Therefore the content and applications must be adapted to each channel. Since new devices and content emerge continuously, this adaptation must be made to work for new devices not originally envisioned. In addition, it is important to be able to adapt existing content that may not have been created with this multi-channel or multi-modal deployment model in mind.
Recently multiple standard activities have been initiated to address related issues [5,6,7,8]. We should also point to the W3C XFORMS, DOM and XHTML generalized UI events as closely related activities.
It is also important to note that multi-channel and multi-modal applications are by definition offering support for Web Accessibility [6]. If approaches like single authoring be widely accepted, then most of the Next Web content will automatically be accessible to a wide variety of users with disabilities.
Content targeted at multiple channels can be created by multiple authoring:
- Separate authoring of the application in each target
channel.
- Authoring of style sheet transformations of a
common representation (device-independent) into the different target presentation
languages (final form).
In addition, for multi-modal applications, the developer must also specify the synchronization of the different channels.
We feel there is a strong need for a language that supports single authoring across a large variety of devices and modalities.
Single authoring is motivated by the need to author, maintain, and revise content for delivery to an ever-increasing range of end-user devices. Separate authoring of the target pages leads to the M times N problem: an application composed on M pages to be accessed via N devices requires M x N authoring steps and it results into M x N presentation pages to maintain. Generic separation of content from presentation results into non-re-usable style sheets and a similar M x N problem with the style sheets. Using an intermediate format with two-step adaptation calls for M+N reusable transformations to be defined. Appropriate definition of a standard common intermediate format allows the M content-to-intermediate authoring steps or transformations - one for each page - to be defined by content domain experts while the N intermediate-to-device transformations can be programmed by device experts.
Because of the rate at which new devices are becoming available, the system must be able to adapt content for new devices that were not envisioned when the content was created. In addition, it is important to be able to adapt existing content that may not have been created with this multi-channel deployment model in mind.
Eventually, multiple authoring is an even more complex problem if synchronization
is needed across channels. Indeed, with multiple authoring approaches, the
application developer must explicitly author where the different channels (or
views) of the applications must be synchronized. Today this can be done by using
explicit synchronization tags (co-visit URL tags that indicate that when
reaching this item a new page must be loaded by the other view) or merged pages
(where the application is authored by combining snippets from each synchronized
modality). Besides having strong consequences on the underlying browser
architecture, these approaches lead to combinatorial amounts of
authoring:.
- between every pair (or more!) of channel to
synchronize.
- whenever a different granularity level of the
synchronization is required.
In the near future, it is to be expected that numbers of multi-modal browser implementation will be distributed. It will therefore be especially advantageous to support adaptation the granularity level of synchronization across the views to the network load or available bandwidth. Adaptation to the user's preferences or browser capabilities should also be supported. How will it ever be possible to author and maintain multi-modal applications with such a combinatorial explosion of application versions?
Clearly multiple authoring approaches, at least as we understand them today, are not viable long term. Significant inventions are still needed. As described below, single authoring leads to a simplification of the synchronization authoring and renders the problem manageable.
We advocate a programming approach that enables separation of specific content from the presentation enabling reusable style sheets for default presentation in the final form. Specialization can then be performed in-line or via channel specific style sheets.
The underlying principle of single authoring is the Model View Controller:
- The channel independent description of the application
constitutes the model
- Channels are views of this model. These
views are obtained by transforming the model representation into its target form
which is rendered by channel specific browsers (e.g. WAP browser, Web / HTML browser , C-HTML browser, HDML browser,
VoiceXML voice browser, etc.
).
- The user interacts with the view through the browser.
Separating content from presentation in order to achieve content re-use is now the accepted way of deploying future information on the World Wide Web. In the current W3C architecture, such separation is achieved by representing content in XML that is then transformed to appropriate final-form presentations via XSL transforms. Other transformation mechanisms could be considered.
What is new here is the ability to structure the content to achieve
presentation re-use as well.
Multi-modality can be considered as a particular type of channel.
During multi-modal or multi-device interactions, the MVC principle becomes especially relevant. The user interacts via the controller on a given view. Instead of modifying the view, his or her actions update the state of the model. It results in an update of the different registered views to be synchronized. Details can be found in [2,4].
Single authoring for delivering to a multiplicity of synchronized target devices and environment has one final crucial advantage. As we evolve towards devices that deliver multi-modal user interaction, single authoring enables the generation of tightly synchronized presentations across different channels, without requiring re-authoring of the multi-channel applications. The MVC principle guarantees that these applications are also ready for synchronization across channels.
Such synchronization allows user intent expressed in a given channel to be propagated to all the interaction components of a multi-modal system. We speak of tightly coupled multi-modal interactions by opposition to loosely coupled multi-modal interactions where each channel has its own model that periodically synchronizes with the models associated to the other channels. A tightly coupled solution can support a wide range of synchronization granularities. It also allows optimization of the interaction, by allowing given interactions to take place in the channel that is best suited as well as to revert to another channel when it is not available or capable enough.
The same approach can be extended to multi-device browsing where now an application is simultaneously accessed through different synchronized browsers.
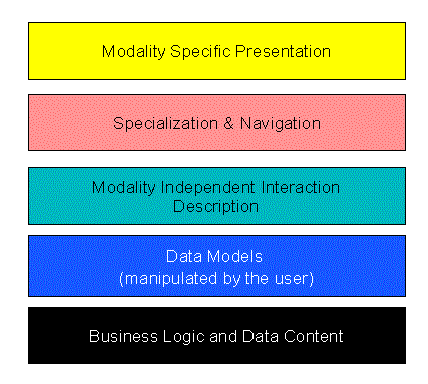
We propose to achieve single authoring by realizing that in addition to content and presentation, there is a third component, the interaction, that lies at the heart of turning static information into interactive applications. This is abstractly illustrated in figure 1.
The application is developed in a representation that is independent of the target channel. Such representation describes abstractly the interaction and the data model that the user manipulates through it. At that level, the application is fully functional, independently of the modality or device where it will be rendered. Dynamic content and backend access to the business logical are conventionally programmed.
The application can be transformed into presentations (final form) using default transformation rules that depend only on the target channel. Such presentations are defaults views of the applications adapted to the channel.
The application can now be specialized to specific channels or classes of channels. This can be done in-line or by specializing specific transformation rules. In particular such specialization can address the navigation flow, cosmetic layering and nature of the content finally presented to the user in each channel or channel class.
We believe that the specialization of a fully functional channel-independent version of the application is an very efficient way to develop and maintain multi-channel applications.
In addition, the existence of a modality independent representation of the applications enable implementation of the MVC, where the state of the application in that representation can be considered as the model of the MVC architecture.
The single authoring for a multiplicity of interfaces and deployment environments described above necessarily involves addressing of issues of presentation specific to each channel e.g., designing the look and feel for each visual presentation, the sound and feel for each auditory representation. We believe that a single authoring framework can allow these concerns to be cleanly separated so that:
· Content can be created and maintained without
presentation concerns.
· Presentation rules --including content
transformations and style sheets can be maintained for specific channels
without adversely affecting other aspects of the system.
· Content and style can be independently
maintained and revised.
· The result can be specialized for a specific
channel.
This separation corresponds also to an advantageous separation of the programming tasks and skills that they require.
This short scenario enumerates the advantages of authoring WWW content such as e-commerce applications in a modality-independent single authoring representation over the alternative approach of attempting to transcode content designed for a specific deployment environment, e.g., HTML pages authored for a desktop GUI browser to other modality-specific languages such as VoiceXML or WML. We make these advantages explicit by identifying specific e-commerce scenarios that our approach enables.
In the scenario below, the company names (Bookstore.com and eStore.com) have been selected to be fictitious. It is not the intention to use anybody's registered trademark These are not to our knowledge used names or registered trademarks.
Consider the following end-user deployment scenario. Bookstore.com would like to allow its customers to shop whenever, where ever and how ever the customer finds most convenient. This is because by analyzing its current website traffic, Bookstore.com an electronic store with a well-designed shop front optimized for desktop GUI browsers has discovered that often, customers use the online catalog to locate books of interest; however, not all such searches conclude in a book sale. Further, Bookstore.com has discovered that a few of these incomplete transactions lead to a sale at their traditional bricks and mortar store. BookStore.com now feels that many more of these incomplete transactions could be turned into completed sales if the end user could continue his interrupted transaction using devices such as cell phones. The company has therefore decided to deploy its electronic shop front to a multiplicity of end-user access devices, including handheld computers and cell-phones.
BookStore.com has a significant investment in its current electronic storefront that consists of HTML pages for creating the visual interface and server-side logic for implementing the business backend.
BookStore.com decides to directly leverage this significant ongoing investment in maintaining and updating the visual HTML storefront by contracting out for a transcoder that will translate HTML GUI pages for serving to WML and VoiceXML browsers.
After this new service is deployed, Bookstore.com finds that the customer experience leaves a lot to be desired. End-users complain that though the HTML translations to WML display on their handheld devices or can be access by voice through a VoiceXML browser, the resulting interface and user experience leaves a lot to be desired. This is because the user interface dialogues that result from translating the pages are sub-optimal for the modality being used; for instance, a search for books by Isaac Asimov using the desktop GUI browser produces a long scrollable list that the user can quickly skim --thanks to the large visual display; however, when using the WML browser on a handheld, the list is cumbersome to use. Worse, when interacting with this same dialog over the telephone, the long list is useless because it takes too long to play.
BookStore.com passes this end-user feedback to the authors of the transcoding service who now begin a costly optimization project. As a consequence, many of the WML and VoiceXML pages are now hand-tuned to work around the end-user problems. This hand-tuning is necessary because the WYSIWYG HTML pages that the content creators at Bookstore.com capture the visual appearance --and not the underlying meaning-- of the various transactions offered by the store. Additionally, it is found that many dialogues that can be presented as a single HTML page in the desktop browser need to be split up into multiple dialogues for the other environments; this introduces the need for new server-side logic that is specific to the WML and VoiceXML clients. Finally, the creators of the WML and VoiceXML representations complained after a few months that their pages were breaking because they were not being informed when the WYSIWYG pages got updated. After much wrangling and debate, Bookstore.com management has now introduced a rigorous process for updating content on its storefront --this is to ensure that all versions of its storefront get a chance to be updated synchronously.
This has now reduced some of the earlier friction; however, Bookstore.com now discovers that its site --once known as one of the most up-to-date bookstores-- is now beginning to gain a reputation for being at least six months out of date. It's being quickly out-paced by the competition. In addition, as this process evolves, Bookstore.com finds that in addition to its ongoing investment in maintaining the visual storefront, considerable resources are now spent in keeping the hand-tuned transcodings in sync with the electronic store. Additionally, Bookstore.com also finds that it needs to maintain and update portions of the server-side business backend that are specific to one or other mode of interaction. Finally, Bookstore.com finds its cost of maintaining the HTML storefront going up in order to keep pace with the evolving WWW standards and WWW browser features.
While Bookstore.com loses ground, an innovative company named eStore.com
has quickly gained ground as the electronic store that provides round the
clock ubiquitous shopping. EStore.com storefront is always up-to-date
--both in terms of content, as well as in its ability to keep pace with
the newest WWW browser features and WWW standards. Recently, when a new
handheld browser platform for viewing pages conforming to a newly announced
standard was introduced, the competition at bookstore.com was amazed to
see its rival eStore.com prominently featured on all the portal sites for
the new browser.
So how did they do it?
The engineers at eStore.com had been involved with WWW technology since its inception and had realized that keeping up with the rapid pace of development required creating and maintaining content in a high-level representation that could be translated to the newest standards as they became available. During the infamous WWW browser wars, they had leveraged this ability to serve multiple WWW browsers. As speech technologies became more available, the engineering team at eStore.com realized the potential presented by speech in turning their electronic store into one that was available from a multiplicity of access devices. They participated closely in the definition of specialized languages such as VoiceXML and WML --which they viewed as final form representations for the forthcoming handheld devices in the same vein as HTML was a final form representation for delivering the electronic store to GUI browsers.
Given eStore.com overall architecture of representing their website as a collection of XML-based pages that were appropriately served to different clients, the engineering team was well positioned to take the next step in designing a high-level XML based language that aimed to separate form, content and interaction. Whilst the competition continued to spend resources in authoring modality-specific visual HTML --and subsequently even more resources in translating these to other modality-specific representations such as VoiceXML and WML, eStore.com moved rapidly towards adopting our single authoring markup language for encoding the user interaction logic of their store, and transcoded this representation to legacy browsers.
Since the new proposed markup language representation captured interaction logic --rather than the visual appearance of various user interface dialogues --, optimized versions of the electronic storefront could be delivered to multiple devices. This was because the transcodings to VoiceXML or WML could exploit the semantic information present in the new ML to tune the shape of the user interface dialogues. This is one of the most significant advantages of the new markup language over the more pedestrian approach of transcoding HTML directly. Given this advantage, eStore.com was able to deploy a small engineering team to transcode the new ML page to any of the many desired final-form representations such as VoiceXML. And better yet, the best was still to come ...
As customers flocked to the eStore.com site, they asked for more innovative features such as the ability to interact with the site using multiple modalities in parallel, especially now that new 3G Voice/WAP devices are being released. The engineering team at eStore.com spotted the potential benefits and designed a multi-modal browser that allowed multi-modal interaction where the user interface dialogues in the various modalities were tightly synchronized. This was possible to do because the various modality-specific UI dialogues were being generated from a single representation; and rendered using a single model; as a consequence, the multiple user interfaces e.g., GUI, speech, etc. could be synchronized and continuously updated as user interaction proceeded with one modality or another. With such an interface, users could to switch modality at any time and seamlessly continue the on-going transaction. eStore.com is now considered a textbook example of a successful e-business born on the Next Web.
The proposed programming model is illustrated in the figure1.
In our implementation the data models manipulated by the user
is specified using Xforms [10]. The modality independent representation of the
application in terms of interactions is bound to Xfroms according to the Xforms
separation of UI from data models (W3C work in progress).
The interaction layer abstracts the application in terms of a
finite set of interaction primitives or conversational gestures. These gestures
are defined as the elementary components of interaction, independent of the modalities.
The set can be expanded by the application developer if needed. Examples of such
gestures and gesture components are:
- selection out of a list (exclusive or not)
- Message to the user
- Submission action
- Free input
- etc..
Defaults rendering of these conversational gestures depend only of the gesture and the target modality or channel.
For example consider an application that welcomes a user at a bar (Global Cafe) and offers him or her the capability to order the drink in advance. The simple HTML version of the application is illustrated in figure 2. This is intentionally a very simple example intended to explain the approach. Detailed specifications of the data model and vocabularies used to specify the different layers will be published later on elsewhere.
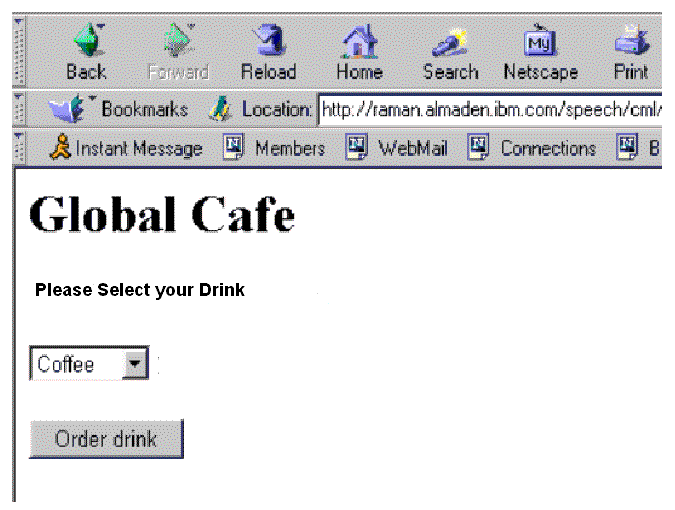
At the level of the interaction and data model layer, the application can be described as: 1) Message to the user (Welcome to the Global cafe), 2) Message to the user (Please Select your drink) 3) Selection from a list (dynamically generated by the backend - business logic and data content; and specified via Xforms) 4) Action: submit.
This description of the application is totally independent of the target channel, and it is fully functional.
Default rendering in a given channel is only a function of the target channel
not the application. For example, the gesture "selection out of a list"
can be rendered by default as:
- HTML Rendering: Pull Down Menu
- WML: Radio buttons, possibly fragmented over multiple decks
of cards
- VoiceXML: The spoken dialog can be very simple (and ill
designed) when the whole list is presented to the user for selection. More
advanced dialogs with a completely differnet dialog flow for speech can be
provided: "there are 50 items to select from, here ar ethe first three,
please say more if you want to hear more", or NLU/free form dialogs.
The transformations can be implemented via XSL style sheets.
Clearly this approach supports different dialog flow in each modalities.
Clearly also the resulting default rendering for each channel may be considered as quite bland. This justifies the specialization step with in-line specialization (pass-through and gesture extensions) or specialization of the transformation rules.
Using the MVC architecture afore mentioned, it is possible to support synchronization of the application at multiple levels (page level, gesture level, intra gesture level or event level).
Figure 3 illustrates the MVC architecture and how it can be implemented with existing channel specific browsers.
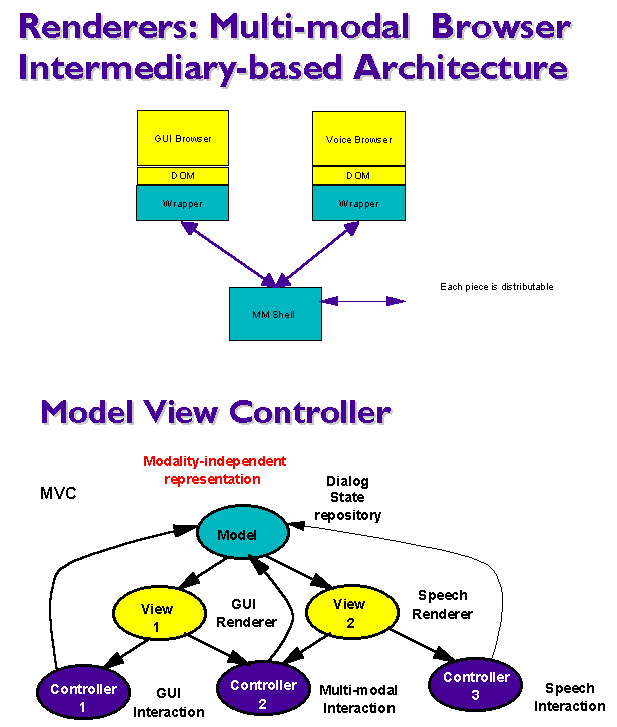
The proposed architecture enables the implementation of multi-modal browser using existing channel specific browsers, provided that they support at least a level 2 DOM architecture. The Wrapper can filter events to adjust to the desired granularity level of synchronization. The use of a common model authored by single authoring guarantees consistency of the interface and automatic support of these different granularity.
Note that this is to be contrasted with multi-modal browser implementations like co-browser or command and control voice interface to a GUI applications. In the first case, consistency can not be guaranteed as the views may not be in the same state. It depends on the assumptions made by the application developer at authoring. In the latter case, the voice view is not a fully functional application, it only drives changes of states in the GUI application. At best, it can support navigation and select menus. But it can not support input gestures without requiring multiple authoring.
Note also that this MVC architecture and implementation also supports multiple authoring approaches. The specialization step of the single authoring programming model can also include specialization of the synchronization with explicit tags. This would also require modification of the channel specific browsers.
Figure 4 illustrates a distributed multi-modal WAP browser architecture.
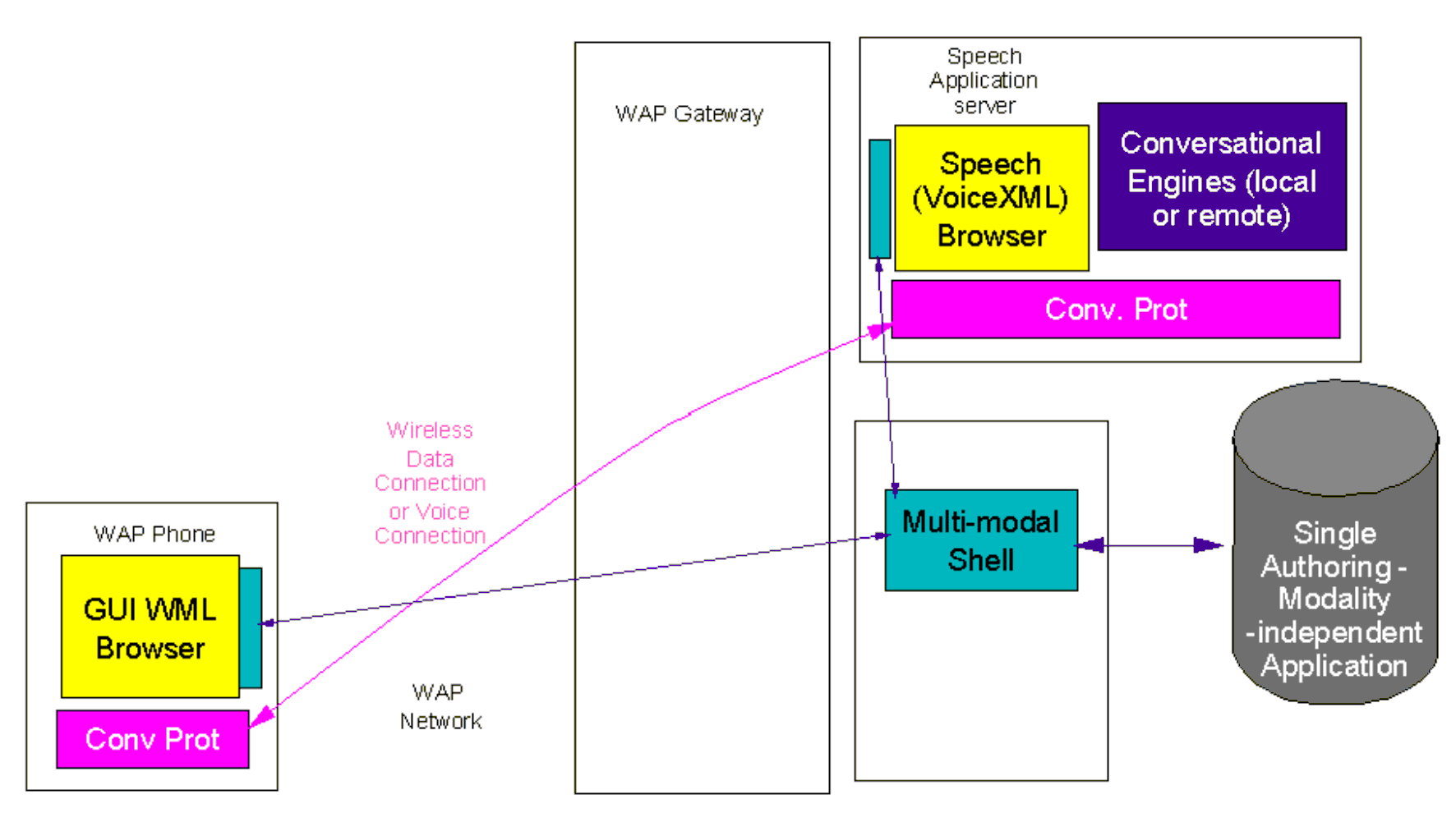
This architecture assumes:
- Push support by WAP (Wap 1.2)
- A WML DOM specification
- A WML browser with a DOM L2 interface
- Support of Voice over Data (GPRS) or conversational
coding and protocols (data only connections) [11,12,13].
While not available today, these feature will be deployed in the coming years.
This section contains our abstract requirements for a single authoring language for multi-channel and multi-modal applications. The implementation examples provided above further motivates these requirements.
- XML compliant
- Vendor neutral
- Any tool developer can target it or use it as an input representation
- It can be used not only to express data within an application, but also to pass it to a network services provider, portal, or directly to an end-user device
- A single authoring process should handle both multi-channel applications and multi-modal applications
- Supports channel-independents interaction description
- Can be mapped using style sheets to an open-ended set of device specific markups including VoiceXML, WML, CHTML, HTML and others.
- Support full function programming; enabling rich-function devices such as desktop browsers
- Extensible to allow new interaction or presentation model abstractions
- Can accommodate channel- or device-specific specialization either in-line, as annotations, or using style sheets
- Supports a developer-definable hierarchy of channels and devices
- Supports specification of data models in Xforms / Xschema to model the data that can be manipulated by the end user
- Enables fine-grain synchronization of multi-modal interaction
- Enables specialization of the synchronization
- Can accommodate both synchronous and asynchronous data exchange, and connected as well as disconnected operation
In addition, for multi-modal rendering, we recommend to leverage the forthcoming DOM level 2 specifications to enable the implementation of the MVC with legacy browsers [2,4]. It implies that the supported channel specific languages must have a DOM level 2 (or higher) standardized specification.
The scope of single authoring is not limited to multi-channel or multi-modal applications. Provided that an underlying platform supports management of I/O abstract events, dialog management, arbitration and context management, single authoring can be extended as the programming model of conversational applications where the interaction or dialog is now free flow [4].
Conversational applications support multi-modal, free flow interactions (mixed initiative dialogs) within applications and across independently developed applications, and using short term and long term context (including previous input and output) to disambiguate and understand the users intention. Typically makes use of Natural Language Understanding (NLU).
The description of the application in terms of the data model that the user must "complete" (mandatory or optional) and the description of how the user interacts with it to fill this data model is all what is needed for a dialog manager to drive a conversational dialog.
At this stage, dialog management and arbitration algorithms are still mostly domain specific and they require very complex learning and tuning stages. Therefore, advances to provide generic conversational user interfaces and platforms require parallel progresses in these core algorithms. This observation is as true for single authoring as for other authoring methods. However, our experiences shows the single authoring again appropriately separates the programming tasks. In other words, it cleanly decouples the programming of the dialog management and arbitration algorithm from the authoring of the application. Today, with the current limitations of the technology, it can already be widely used to more easily author, modify and maintain applications within the limits of the associated application domain.
Today, mixed initiative is addressed or scoped by the VoiceXML forum [9] and the W3C Voice Browser working group [8]. We have hinted here that free flow interactions will probably rapidly be addressed by other standard activities related to multi-channel or multi-modal. Depending if the reader believes that multi-modal user interfaces will precede or follow free flow interfaces, it is worth immediately adding conversational application authoring to the scope of any single authoring activity. Conversely, voice standard activities should be aware and consider single authoring as a recommended direction.
It is important to realize that the single authoring programming model that we have introduced here is not limited to declarative programming. Imperative and hybrid (declarative + scripts and imperative code) can follow the same rules but typically it then requires the presence of supporting platforms.
We have illustrated how a single authoring programming model can address and greatly facilitate the authoring and maintenance of Next Web applications. At this stage, we strongly recommend that these approaches be widely studied, validated. As it is usually a slow process, we also recommend that interested parties initiate a single authoring standardization effort to facilitate the introduction and acceptance of this new approach.
This paper hints how the single authoring programming model will probably be a key component of the Next Web. It is also to our knowledge the first approach that while offering immediate multi-channel advantages, clearly open the door to smooth migration to multi-modal and conversational applications.
[2] S. H. Maes and T. V. Raman, Multi-modal interaction in the Age of Information Appliance, in Proceedings ICME 2000, July 2000, New York, USA.
[3] R. B. Case, S. H. Maes and T. V. Raman, Position paper for the W3C/WAP Workshop on the Web Device Independent Authoring, W3C/WAP joint Workshop on Web Device Independent Authoring, Bristol, October 2000.
[4] S. H. Maes, Elements of Conversational Computing - A Paradigm Shift, ICSLP 2000, Beijing, October 2000.
[5] W3C/WAP Workshop: the Multimodal Web, Hong Kong, HK, September 2000, http://www.w3.org/2000/09/Papers/Agenda.html
[6] W3C/WAP Workshop: Web Device Independent Authoring, Bristol, UK, October 2000, http://www.w3.org/2000/10/DIAWorkshop/
[7] ETSI STQ Aurora DSR Working Group, Applications and protocols sub-group
[8] W3C Voice Browser working group, Multi-modal Sub-group, http://www.w3.org/Voice/
[9] VoiceXML Forum, http://www.voicexml.org
[10] W3C Xforms working group, http://www.w3.org/MarkUp/Forms/
[11] S. H. Maes, D. Chazan, G. Cohen, R. Hoory, Conversational Networking: Conversational protocols, for transport, coding and control, ICSLP 2000, Beijing, October 2000.
[12] VoiceTIMES consortium, http://www.ibm.com/voicetimes/
[13] ETSI STQ Aurora DSR Working Group